
LLaVA-o1, Çin’deki birçok üniversiteden araştırmacılar tarafından geliştirilen bir model, OpenAI’nin o1 modelinden ilham alarak açık kaynaklı görsel-dil modellerinde (VLM) yeni bir standart belirliyor. Model, yapay zeka dil modellerinin mantıksal akıl yürütme yeteneklerini geliştiren “inference-time scaling” (çıkarım sırasında ölçekleme) paradigmasını görsel-dil alanına taşıyor.
Görsel-Dil Modellerinde Yapılandırılmış Akıl Yürütme
Geleneksel açık kaynaklı VLM’ler genellikle doğrudan tahmin yöntemleri kullanır ve metin istemlerini analiz ederken akıl yürütme zincirleri oluşturmaz. Bu nedenle, bu modeller mantıksal akıl yürütme gerektiren görevlerde sınırlı kalır ve hata yapma veya hayal ürünü cevaplar üretme eğilimindedir.
Araştırmacılar, mevcut VLM’lerin akıl yürütme süreçlerinin sistematik ve yapılandırılmış olmadığını gözlemledi. Bu eksiklik, modellerin problem çözme sürecinde hangi aşamada olduklarını ve hangi sorunu çözmeleri gerektiğini tam olarak anlayamamalarına yol açıyor.
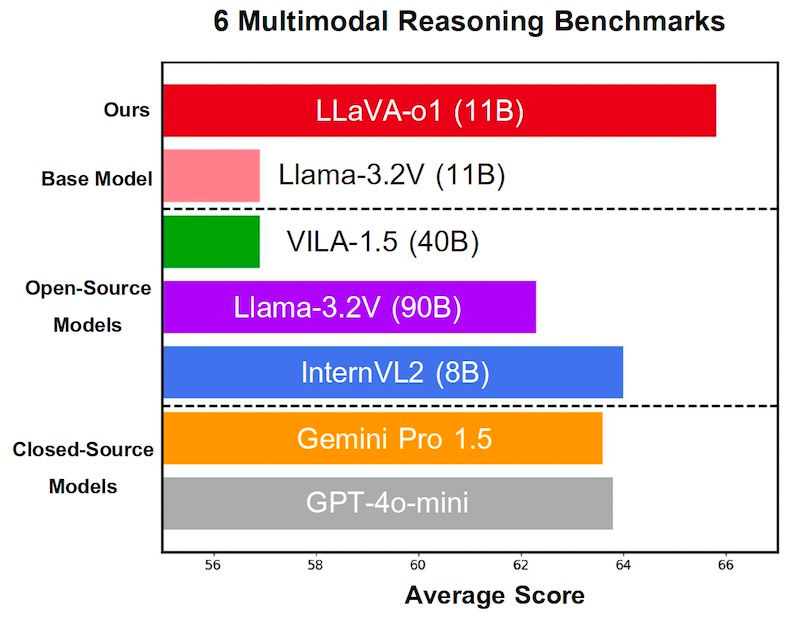
LLaVA-o1 ve diğer açık ve kapalı modeller karşılaştırması Kaynak: arXiv
LLaVA-o1, dört aşamalı bir akıl yürütme süreci tasarlayarak bu sorunu çözüyor:
- Özet: Model, sorunun temelini özetler ve ana problemi belirler.
- Açıklama: Görseller varsa, ilgili kısımları tanımlar ve soruyla ilişkili unsurlara odaklanır.
- Akıl Yürütme: Özetten yola çıkarak yapılandırılmış ve mantıksal bir akıl yürütme süreci yürütür.
- Sonuç: Önceki akıl yürütmeye dayalı olarak kesin ve kısa bir cevap sunar.
Bu süreçte sadece sonuç kullanıcıya görünür, diğer üç aşama modelin iç akıl yürütme süreci olarak işler.
Aşamalı Akıl Yürütme ve Beam Search Teknolojisi
LLaVA-o1, “stage-level beam search” adını taşıyan yeni bir çıkarım ölçekleme tekniği sunuyor. Bu teknik, her akıl yürütme aşamasında birden fazla aday çıktı üreterek en iyisini seçiyor. Bu yapılandırılmış yaklaşım, LLaVA-o1’in daha doğru ve verimli sonuçlar üretmesini sağlıyor.
Modelin Eğitimi ve Değerlendirmesi
Araştırmacılar, LLaVA-o1’i eğitmek için yaklaşık 100.000 görsel-soru-cevap çiftinden oluşan yeni bir veri seti oluşturdu. Bu veri seti, çoklu soru-cevap oturumlarından geometrik akıl yürütmeye kadar çeşitli görevleri kapsıyor. GPT-4o modeli, her örnek için dört aşamalı akıl yürütme sürecini oluşturmak üzere kullanıldı.
Model, bu veri seti üzerinde ince ayar yapılarak geliştirildi ve birkaç çok modlu akıl yürütme benchmark’ında değerlendirildi. Sonuçlar, LLaVA-o1’in temel Llama modeline kıyasla ortalama %6,9 oranında bir performans artışı sağladığını gösterdi.
Rekabetçi Performans
LLaVA-o1, yalnızca aynı boyuttaki veya daha büyük açık kaynaklı modelleri geride bırakmakla kalmadı, aynı zamanda GPT-4-o-mini ve Gemini 1.5 Pro gibi kapalı kaynaklı modelleri de geçti. Bu başarı, modelin hem performans hem de ölçeklenebilirlik açısından yeni bir standart oluşturduğunu kanıtlıyor.
Gelecek Araştırmalar İçin Bir Yol Haritası
Araştırmacılar, LLaVA-o1’in çok modlu akıl yürütme alanında yapılandırılmış akıl yürütme için bir temel oluşturduğunu belirtiyor. Gelecekteki araştırmalar, dış doğrulayıcılar ve takviye öğrenimi gibi yöntemlerle daha karmaşık görevlerde performansı artırmayı hedefliyor.
Comments are closed